第四回【python】【業務効率化】【ファイル統合】複数のExcel(エクセル)ファイルを自動化で1つのファイルにしたい -4-
- 2020.10.24
- python
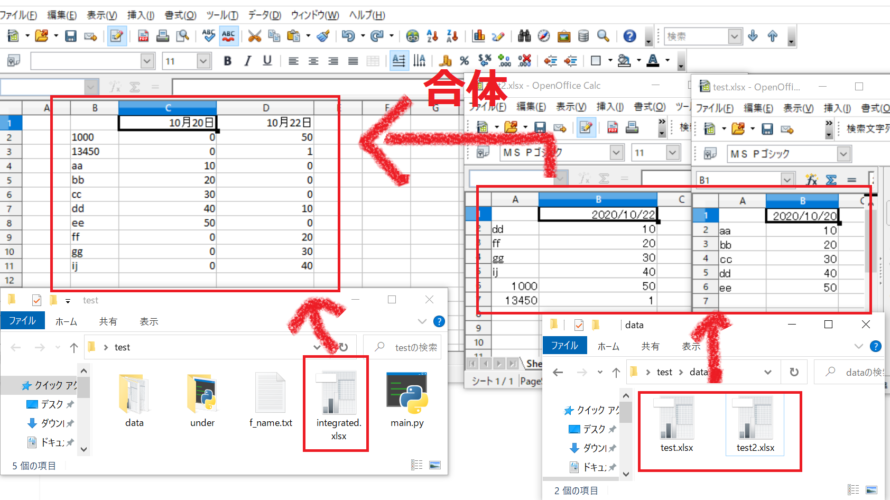
業務効率化のため特定のフォーマットで出力された複数のエクセルファイルをpythonで自動的に1個にまとめることを目標にします。
第四回で読み込みから書き込みまでが完了します。業務効率化が目的なのでpythonを使わない人でも使えるように、ファイル名などの定数は「.py」のプログラムを触らなくても使えることを目指します。【注】この記事のみでは完結しません。
【参考】
複数のExcel(エクセル)ファイルを自動化で1つのファイルにしたい 1
→統合前のエクセルファイルの名前を取得
複数のExcel(エクセル)ファイルを自動化で1つのファイルにしたい 2
→エクセルデータの読み込み
複数のExcel(エクセル)ファイルを自動化で1つのファイルにしたい 3
→X軸データの重複削除
複数のExcel(エクセル)ファイルを自動化で1つのファイルにしたい 4
→データ加工と保存(一通り終了)
【今回のプログラム一式】
サンプルコード
# -*- coding: utf-8 -*-
import os
import sys
import codecs
from os import path
import openpyxl
from openpyxl import load_workbook
##自作モジュールのインポート##
m_path = path.join(path.dirname(__file__),"under")
sys.path.append(m_path)
import yomikomi
column=[] #第3回で追加
all_xy=[]#第4回で追加
header=[]#第4回で追加
###↓↓↓↓↓↓第1回で説明↓↓↓↓↓↓↓↓###
###f_name.txtの読み込み###
rf_name="f_name.txt"
read_path = path.join(path.dirname(__file__),rf_name)
read_file=yomikomi.d_yomikomi(read_path)
#print(read_file)
###f_name.txtから3行目のみ抜き取る####
d_f_name=read_file[2]
x=d_f_name.find("\r\n")
d_f_name=d_f_name[0:x]
#print(d_f_name)
#####################################
###統合するファイルの名前を取得####
full_d_f_path= path.join(path.dirname(__file__),d_f_name)
files = os.listdir(full_d_f_path)
#print(files)
####################################
###↑↑↑↑↑↑↑↑第1回で説明↑↑↑↑↑↑↑↑↑###
#
"""
##################################################
第2回:フォルダに入れた複数のエクセルファイルを読み取る
第3回:複数のエクセルファイルのX軸(1列目)を1つにする
#################################################
"""
#
###↓↓↓↓↓↓第2回で説明↓↓↓↓↓↓↓↓###
###f_name.txtの読み込み###
for i in files:
# print(i)
f_path= path.join(path.dirname(__file__),d_f_name,i)
# print(f_path)
#ファイル読み込み
wb=openpyxl.load_workbook(f_path)
#ワークシート一覧読み込み
ws=wb.sheetnames
#先頭のワークシート読み込み
ws0_name=ws[0] #ワークシートの名前を取り出し(sheet1)
ws0=wb[ws0_name] #sheet1のデータをws0に代入
# print(ws0)
###↑↑↑↑↑↑↑↑第2回で説明↑↑↑↑↑↑↑↑↑###
head=ws0["B1"].value#第四回で追加
header.append(head)#第四回で追加
###↓↓↓↓↓↓↓↓第2、3回で説明↓↓↓↓↓↓↓↓↓###
xx=[]
yy=[]
xy=[[],[]]
for row in ws0.iter_rows(min_row=2):
xx.append(str(row[0].value))
yy.append(row[1].value)
xy=[xx,yy]
all_xy.append(xy)
# print(xy)
for row in ws0.iter_rows(min_row=2):
column.append(str(row[0].value))#文字列として1列目を保存
#print(column)
delete_column=set(column)#重複の削除
#print(delete_column)
column2= sorted(delete_column)
print(header)#第四回で追加
print(column2)
print(all_xy)
###↑↑↑↑↑↑↑↑第2、3回で説明↑↑↑↑↑↑↑↑↑###
"""
############################################
読み取ったエクセルデータを書き込み用リスト形式に変換
###########################################
"""
full_data=[]
full_data.append(column2)
num=0
for num,xy_data in enumerate(all_xy):
xxx=[]
# print(xy_data)
test=xy_data
test_x=xy_data[0]
test_y=xy_data[1]
# print(test_x)
# print(test_y)
for t_col_data in column2:
flag=0
for num2,x_data in enumerate(test_x):
# print(t_col_data,":",x_data)
if t_col_data==x_data:
# print(test_y[num2])
xxx.append(test_y[num2])
flag=1
if flag==0:
xxx.append(0)
full_data.append(xxx)
print(full_data)
#
"""
##########################################
エクセルファイルにpython上のデータを保存
#########################################
"""
#
###f_name.txtから7行目を抜き取り(保存ファイル名)####
d_f_name=read_file[6]
x=d_f_name.find("\r\n")
w_f_name=d_f_name[0:x]
#######################################################
###保存ファイルのパスを作成############################
w_f_path= path.join(path.dirname(__file__),w_f_name)
#######################################################
book = openpyxl.Workbook()
sheet = book.active# シートを取得し名前を変更する
sheet.title = 'First sheet'
###ヘッダーの保存####
start_row=1 #行
start_col=3 #列
for head_num,head_data in enumerate(header):
sheet.cell(row=start_row,
column=start_col+ head_num,
value=head_data)
###データの保存#####
start_row=2 #行
start_col=2 #列
for num_col,col_data in enumerate(full_data):
for num_row, cell in enumerate(col_data):
sheet.cell(row=start_row + num_row,
column=start_col + num_col,
value=cell)
# ワークブックに名前をつけて保存する
book.save(w_f_path)
####################################
実行結果&解説
18行目でエクセルのxyデータを入れるリストを追加
19行目でエクセルのヘッダーを入れるリストを追加
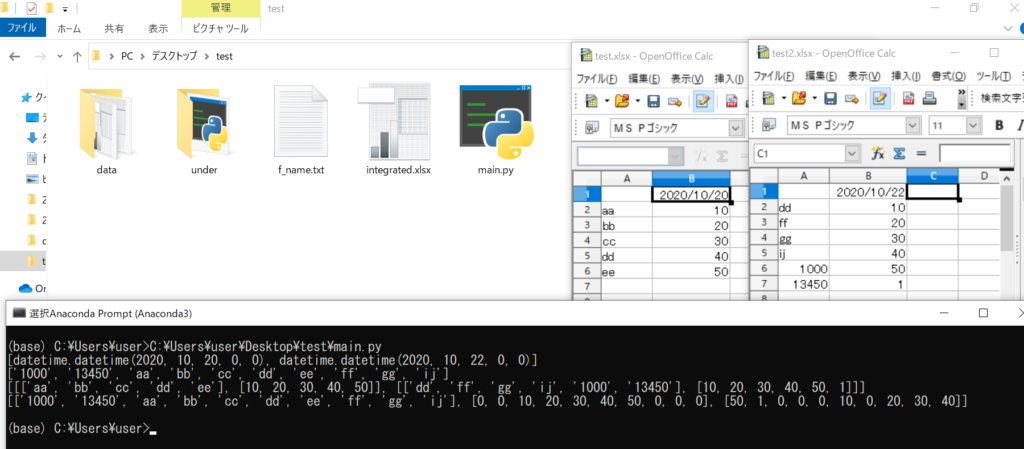
110行目から読み取ったエクセルデータを書き込みがしやすいリスト形式に変換しています。134行目の判別で同じxデータがある場合はyデータを挿入し、flagを立てます。同じxデータがない場合はy=0とします(flagが立っていない場合)。python実行画面の最後の行が141行目でprintしたfull_dataで最終的に出来上がるリストになります。
149行目からリスト形式のデータをエクセルに保存していきます。
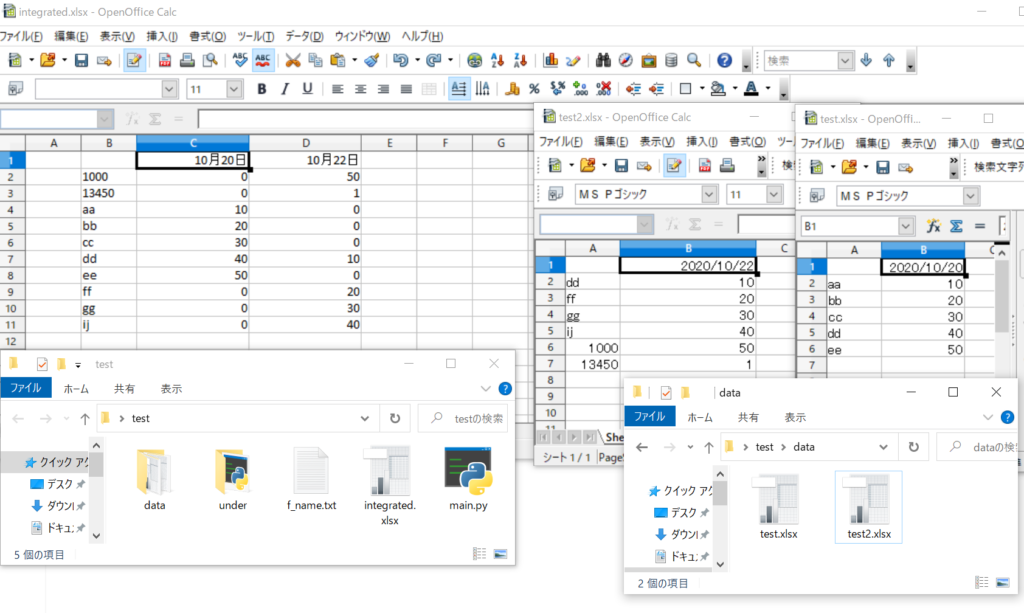
156行目から164行目で保存するエクセルファイルの名前を取り出してパスを作成しています。(※今回はf_name.txtの7行目に記載してあります。下記を参照ください)今回の保存先のファイル名はintegrated.xlsxで、保存先は実行したmain.pyと同じフォルダとなります。
167~169行目で保存するエクセルデータにシートを作成して名前を付けます。
173~180行目で作成したエクセルシートにヘッダーを入れます。
185~194行目でfull_dataに格納したデータをエクセルシートに入れます。
197行目で163行目で作成したパスの位置にエクセルファイルを保存します。このとき同じ名前のファイルがある場合は上書き保存されます。下記の結果ではフォルダ上にintegrated.xlsxが作成され、main.pyが終了します。
【f_name.txt】
■エクセルファイルを入れたフォルダを記載してください
↓↓↓↓↓↓↓↓統合したいエクセルが入ったフォルダ↓↓↓↓↓↓↓↓
data
↑↑↑↑↑↑↑↑統合したいファイル↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
■エクセルファイルを保存したいフォルダを記載してください
↓↓↓↓↓↓↓↓統合後の名前↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
integrated.xlsx
↑↑↑↑↑↑↑↑統合後の名前↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
※注:3行目にフォルダの名前入れてください
※注:7行目にフォルダの名前入れてください【integrated.xlsx】
あとがき
複数回にまたがってしまいましたが一通りの処理が作成できました。今回は自分で重複削除でX軸を調整したり、その軸に合わせてデータを入れていきましたが、もっと簡単な方法があるかもしれません。また、修正を繰り返して何とか動いたところですのでバグ等あるかもしれませんので参考にされる方はご注意ください。
次回以降で関数化や定数ベタ打ちのところを外部txtから読めるようにして使いやすくしていきたいと思います。
-
前の記事
第三回【python】【業務効率化】【ファイル統合】複数のExcel(エクセル)ファイルを自動化で1つのファイルにしたい -3- 2020.10.22
-
次の記事
【python】テキストから特定の行を取り出す 2020.10.26